Вы достигли нового уровня
1. Рекурсия
- Привет, Амиго. Сегодня Билаабо расскажет тебе, что такое рекурсия.

Как ты знаешь, в Java одни методы вызывают другие методы. При этом, при вызове метода, в него передаются конкретные значения аргументов, а во время его работы локальные переменные метода принимают некоторые значения.
- Ага.
- И как ты знаешь, внутренние переменные разных методов независимы друг от друга.
- Ага.
- Так вот, представь ситуацию, когда метод может вызвать сам себя. Именно она называется рекурсией. Пример:
| Пример |
|---|
| public static void main(String[] args) { countDown(10); } public static void countDown(int x) { if (x <=0) System.out.println("Boom!"); else { System.out.println(x); countDown(x - 1); } } |
| Вывод на экран: |
| 10 9 8 7 6 5 4 3 2 1 Boom! |
- Честно говоря, вижу, что метод в коде сам себя вызывает, но не понимаю, что именно при этом происходит.
- Да примерно тоже, что и при вызове другого метода.
- Нет, я спрашиваю, что происходит с переменными? С их значениями? И как мы выходим из метода? Или мы выходим из всех сразу?
- Господи. Да все гораздо проще. Представь что метод, который вызывает сам себя, размножили много раз. Тогда будет аналогичная ситуация:
| Рекурсивный вызов метода | Что происходит «на самом деле» |
|---|---|
| public static void main(String[] args) { countDown(10); } public static void countDown(int x) { if (x <=0) System.out.println("Boom!"); else { System.out.println(x); countDown(x - 1); } } |
public static void main(String[] args) { countDown1(3); } public static void countDown1(int x) { if (x <=0) System.out.println("Boom!"); else { System.out.println(x); countDown2(x - 1); } } public static void countDown2(int x) { if (x <=0) System.out.println("Boom!"); else { System.out.println(x); countDown3(x - 1); } } public static void countDown3(int x) { if (x <=0) System.out.println("Boom!"); else { System.out.println(x); countDown4(x - 1); } } public static void countDown4(int x) { if (x <=0) System.out.println("Boom!"); else { System.out.println(x); countDown5(x - 1); } } |
| Вывод на экран: | Вывод на экран: |
| 3 2 1 Boom! |
3 2 1 Boom! |
Т.е. каждый раз, при вызове метода (даже самого себя), создаются новые переменные, которые хранят данные для этого метода. Никаких общих переменных нет.
При каждом вызове в памяти появляется еще одна копия аргументов метода, но уже с новыми значениями. При возвращении в старый метод, там используются его переменные. Т.е. при рекурсии фактически мы вызываем другой метод, но с таким же кодом как наш!
- Ясно. А как работает выход из этих методов? Можно пример?
- Ладно. Один пример стоит тысячи слов. Вот тебе пример:
| Рекурсивный вызов метода | Что происходит «на самом деле» |
|---|---|
| public static void main(String[] args) { print(3); } public static void print(int x) { if (x <=0) System.out.println("Boom!"); else { System.out.println(x); print(x - 1); System.out.println(x); } } |
public static void main(String[] args) { print1(3); } public static void print1(int x) { if (x <=0) System.out.println("Boom!"); else { System.out.println(x); print2(x - 1); System.out.println(x); } } public static void print2(int x) { if (x <=0) System.out.println("Boom!"); else { System.out.println(x); print3(x - 1); System.out.println(x); } } … |
| Вывод на экран: | Вывод на экран: |
| 3 2 1 Boom! 1 2 3 |
3 2 1 Boom! 1 2 3 |
- Ок. Вроде понял. А зачем нужна рекурсия?
- Есть очень много задач, которые разбиваются на отдельные подзадачи, которые идентичны первоначальной задаче. Например, надо обойти все элементы XML-дерева. У каждого элемента может быть несколько дочерних элементов, а у них свои дочерние элементы.
Или тебе нужно вывести список файлов, которые есть в директории и все ее поддиректориях. Тогда ты пишешь метод, который выводит файлы текущей директории, а потом для получения файлов всех поддиректорий вызываешь его же, но с другим параметром – поддиректорией.
Пример:
| Вывод всех файлов на экран из директории и её поддиректорий | |
|---|---|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public static void main(String[] args) { printAllFiles(new File("c:/windows/")); } public static void printAllFiles(File dir) { for (File file : dir.listFiles()) { if (file.isDirectory()) printAllFiles(file); else System.out.println(file.getAbsolutePath()); } } |
Строка 8 – получаем список всех файлов (и директорий) в директории dir.
Строки 10-11 – если файл на самом деле директория, то для вывода ее файлов опять вызываем printAllFiles, но уже с другим параметром – поддиректорией.
Строка 13 – выводим имя текущего файла.
- Ок. Вроде понял. Спасибо, Билаабо.
2. Задачи
- Привет, Амиго! Я отыскал для тебя отличные задания:
| Задачи |
|---|
| 1. Числа Фибоначчи с помощью рекурсии Почитать про числа Фибоначчи. Реализовать логику метода fibonacci, где n - это номер элемента в последовательности Фибоначчи. Не создавайте статические переменные и поля класса. |
| 2. Факториал с помощью рекурсии Почитать про вычисление факториала. Реализовать логику метода factorial, где n - это число, факториал которого нужно вычислить. Не создавайте статические переменные и поля класса. |
| 3. Разложение на множители с помощью рекурсии Разложить целое число n > 1 на простые множители. Вывести в консоль через пробел все множители в порядке возрастания. Написать рекуррентный метод для вычисления простых множителей. Не создавайте статические переменные и поля класса. Пример: 132 Вывод на консоль: 2 2 3 11 |
| 4. Рекурсия для мат.выражения На вход подается строка - математическое выражение. Выражение включает целые и дробные числа, скобки (), пробелы, знак отрицания -, возведение в степень ^, sin(x), cos(x), tan(x) Для sin(x), cos(x), tan(x) выражение внутри скобок считать градусами, например, cos(3 + 19*3)=0.5 Степень задается так: a^(1+3) и так a^4, что эквивалентно a*a*a*a. С помощью рекурсии вычислить выражение и количество математических операций. Вывести через пробел результат в консоль. Результат выводить с точностью до двух знаков, для 0.33333 вывести 0.33, использовать стандартный принцип округления. Не создавайте статические переменные и поля класса. Не пишите косвенную рекурсию. Пример, состоящий из операций sin * - + * +: sin(2*(-5+1.5*4)+28) Результат: 0.5 6 |
3. Сборка мусора
- Привет! Снова решила устроить тебе небольшую лекцию про сборку мусора.
Как ты уже знаешь, Java-машина сама отслеживает ситуации, когда объект становится не нужными и удаляет его.
- Ага. Вы с Ришей раньше мне рассказывали об этом, нюансов я не помню.
- Ок. Тогда повторим.
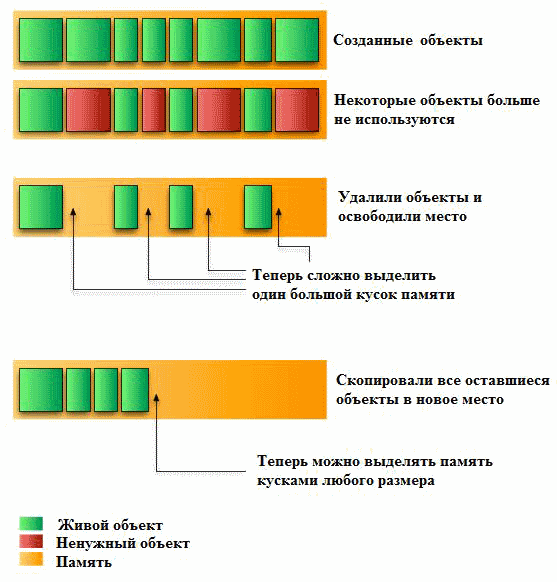
Как только объект создается, Java выделяет ему память. А за востребованностью объекта следит с помощью переменных-ссылок. Объект может быть удален при «сборке мусора» - процедуре очистки памяти, если не остается переменных, которые ссылаются на этот объект.
- А расскажи немного о сборщике мусора, что это такое и как он работает.
- Ок. Раньше сборка мусора происходила в главном потоке/нити. Раз в 5 минут, или чаще. Если наступал случай, когда не хватало свободной памяти, Java-машина приостанавливала работу всех нитей и удаляла неиспользуемые объекты.
Но сейчас от этого подхода отказались. Сборщик Мусора нового поколения работает незаметно и в отдельном потоке. Такую сборку мусора принято называть параллельной.
- Ясно. А как именно определяется – нужно удалять объект или нет.
- Просто считать количество ссылок на объект не очень эффективно – ведь могут быть объекты, которые ссылаются друг на друга, а на которые никто не ссылается.
Поэтому в Java применяется другой подход. Java делит объекты на достижимые и недостижимые. Объект считается достижимым (живым), если на него ссылается другой достижимый (живой) объект. Достижимость считается от нитей. Работающие нити всегда считаются достижимыми (живыми), даже если на них никто не ссылается.
- Ок. С этим вроде ясно.
А как происходит сама уборка мусора – удаление ненужных объектов?
- Тут все просто. В Java память условно разделена на две части, и когда приходит время сборки мусора, все живые (достижимые) объекты копируются в другую часть памяти, а старая память вся освобождается.
- Интересный подход. И не надо считать ссылки – скопировал все достижимые объекты, а все остальные – мусор.
- Там все немного сложнее. Программисты Java выяснили, что объекты обычно делятся на две категории – долгоживущие (которые существуют все время работы программы) и маложивущие (нужны в методах и для выполнения «локальных» операций).
Хранить долгоживущие отдельно от маложивущих гораздо эффективнее. Для этого надо было придумать механизм определения долгожительства объекта.
Поэтому они разделили всю память на «поколения». Есть объекты первого поколения, есть объекты второго поколения и т.д. Каждый раз после очистки памяти, счетчик поколений увеличивается на 1. Если какие-то объекты существуют много поколений, то их записывали в долгожители.
На сегодняшний день Сборщик Мусора очень сложная и эффективная часть в Java. Многие его части работают эвристически – на основе алгоритмов-догадок. Поэтому он часто «не слушается» пользователя.
- В смысле?
- У Java есть объект GC (Garbage Collector – Сборщик Мусора), который можно вызвать с помощью метода System.gc().
Так же можно принудительно инициировать вызов finalize-методов удаляемых объектов, посредством System.runFinalization(). Но дело в том, что по документации Java, это не гарантирует ни начало сборки мусора, ни вызов методов finalize(). Garbage Collector сам решает, что и когда ему вызывать.
- Ничего себе! Буду занять.
- Но и это еще не все. Как ты знаешь, в Java одни объекты ссылаются на другие, и именно с помощью этой сети ссылок определяется – стоит удалять объект или нет.
Так вот, в Java есть специальные ссылки, которые позволяет влиять на этот процесс. Для них есть специальные классы-обертки. Вот они:
SoftReference – мягкая ссылка.
WeakReference – слабая ссылка.
PhantomReference – призрачная ссылка.
- М-да. Чем-то напоминает внутренние классы, вложенные классы, внутренние анонимные классы, локальны классы. Названия разные, но по ним совсем не понятно за что они отвечают.
- Вот, ты Амиго и стал программистом. Теперь ты возмущаешься по поводу названий классов – дескать, недостаточно информативны, и нельзя по одному названию(!) определить, что этот класс делает, как и зачем.
- Ого. А я и сам не заметил. Но это же так очевидно.
Ладно. Соловья баснями не кормят. Давай я тебе расскажу про SoftReference – мягкие ссылки.
Эти ссылки были специально придуманы для кэширования, хотя их можно использовать и для других целей – все на усмотрение программиста.
Пример такой ссылки:
| Пример |
|---|
| //создание объекта Cat Cat cat = new Cat(); //создание мягкой ссылки на объект Cat SoftReference<Cat> catRef = new SoftReference<Cat>(cat); //теперь на объект ссылается только мягкая ссылка catRef. cat = null; //теперь на объект ссылается еще и обычная переменная cat cat = catRef.get(); //очищаем мягкую ссылку catRef.clear(); |
Если на объект существуют только мягкие ссылки, то он продолжает жить и называется «мягкодостижимым».
Но! Объект, на который ссылаются только мягкие ссылки, может быть удален сборщиком мусора, если программе не хватает памяти. Если программе вдруг не хватает памяти, прежде чем выкинуть OutOfMemoryException, сборщик мусора удалит все объекты, на которые ссылаются мягкие ссылки и попробует выделить программе память еще раз.
Предположим, что программа-клиент часто запрашивает у программы-сервера различные данные. Тогда программа сервер может некоторые из них кэшировать, воспользовавшись для этого SoftReference. Если объекты, удерживаемые от смерти мягкими ссылками, будет занимать большую часть памяти, то сборщик мусора просто их поудаляет и все. Красота!
- Ага. Мне самому понравилось.
- Ну и маленькое дополнение: у класса SoftReference есть два метода. Метод get() возвращает объект, на который ссылается SoftReference. Если объект был удален сборщиком мусора, внезапно(!) метод get() начнет отдавать null.
Так же пользователь может сам очистить SoftReference, вызвав метод clear(). При этом слабая ссылка внутри объекта SoftReference будет уничтожена.
На этом пока все.
- Спасибо за интересный рассказ, Элли. Действительно было очень интересно.
4. Задачи
- Что, соскучился? Вот, держи:
| Задачи |
|---|
| 1. Мягкие ссылки Разберитесь в примере. Внутри метода main в нужном месте создайте мягкую ссылку reference на объект monkey. Должны быть только используемые импорты. |
5. weakReference
- И снова здравствуйте!
Сейчас я расскажу тебе еще про одну замечательную штуку - WeakReference – слабые ссылки.
Выглядит она почти так же, как и SoftReference:
| Пример |
|---|
| //создание объекта Cat Cat cat = new Cat(); //создание слабой ссылки на объект Cat WeakReference<Cat> catRef = new WeakReference<Cat>(cat); //теперь на объект ссылается только слабая ссылка catRef. cat = null; //теперь на объект ссылается еще и обычная переменная cat cat = catRef.get(); //очищаем слабую ссылку catRef.clear(); |
У слабой ссылки есть другая особенность.
Если на объект не осталось обычных ссылок и мягких ссылок, а только слабые ссылки, то этот объект является живым, но он будет уничтожен при ближайшей сборке мусора.
- А можно еще раз, в чем отличия межу этими ссылками?
- Объект, который удерживает от смерти только SoftReference может пережить сколько угодно сборок мусора и скорее всего, будет уничтожен при нехватке программе памяти.
Объект, который удерживает от смерти только WeakReference не переживает ближайшей сборки мусора. Но пока она не произошла, его можно получить, вызвав метод get() у WeakReference и вызвать его методы или сделать что-нибудь еще.
- А если на объект ссылаются и SoftReference и WeakReference?
- Тут все просто. Если на объект есть хотя бы одна обычная ссылка – он считается живым. Такие ссылки, кстати, называются StrongReference.
Если на объект нет обычных ссылок, но есть SoftReference, то он – SoftReference.
Если на объект нет обычных ссылок и SoftReference, но есть WeakReference, то он – WeakReference.
Подумай сам, SoftReference защищает объект от удаления и гарантирует, что объект будет удален только при нехватке памяти. WeakReference удерживает объект до ближайшей сборки мусора. SoftReference удерживает от удаления сильнее.
- Ага. Вроде понятно.
- Отлично, тогда расскажу тебе про еще одну занимательную штуку с использованием WeakReference – это WeakHashMap.
- Звучит серьезно!
- А то! WeakHashMap – это HashMap, у которого ключи – это слабые ссылки – WeakReference.
Т.е. ты добавляешь в такой HashMap объекты и работаешь с ними. Все как обычно.
Пока на объекты, которые ты хранишь в WeakHashMap в качестве ключей есть обычные (сильные или мягкие) ссылки, эти объекты будут живы.
Но, представь, что во всем приложении больше не осталось ссылок на эти объекты. Все что удерживает их от смерти – это несколько WeakReference внутри WeakHashMap. Тогда после ближайшей очистки мусора такие объекты исчезнут из WeakHashMap. Сами. Как будто их там и не было.
- Не уверен, что понял.
- Ты хранишь в WeakHashMap пары объектов – ключ и значение. Но WeakHashMap ссылается на ключи не прямо, а через WeakReference. Поэтому, когда объекты, используемые в качестве ключей, станут слабодостижимыми, они уничтожатся при ближайшей сборке мусора. А значит, из WeakHashMap автоматически удалятся и их значения.
В WeakHashMap очень удобно хранить дополнительную информацию к каким-то объектам.
Во-первых, ее очень легко получить, если использовать сам объект в качестве ключа.
Во-вторых, если объект будет уничтожен, он сам исчезнет из HashMap и все данные, что были к нему привязаны.
Пример:
| Пример |
|---|
| //создаем объект для хранения дополнительной информации о пользователе WeakHashMap<User, StatisticInfo> userStatistics = new WeakHashMap<User, StatisticInfo>(); //кладем информацию о пользователе в userStatistics User user = session.getUser(); userStatistics.put(user, new StatisticInfo (…)); //получаем информацию о пользователе из userStatistics User user = session.getUser(); StatisticInfo statistics = userStatistics.get(user); //удаление любой информации о пользователе из userStatistics User user = session.getUser(); userStatistics.remove(user); |
| 1.Внутри WeakHashMap ключи хранятся в виде WeakReference<User>. 2.Как только объект user будет уничтожен сборщиком мусора, в WeakHashMap неявно вызовется метод remove(user) и любая «привязанная» к объекту user информация, будет удалена из WeakHashMap автоматически. |
- Выглядит как мощный инструмент. А где можно его использовать?
- По обстоятельствам. Ну, допустим, у тебя в программе есть нить, которая отслеживает работу некоторых объектов-заданий и пишет информацию о них в лог. Тогда эта нить может хранить отслеживаемые объекты в таком WeakHashMap. Как только объекты станут не нужны, сборщик мусора удалит их, автоматически удалятся и ссылки на них из WeakHashMap.
- Звучит интересно. Сразу чувствуется, ну не писал я еще серьезных программ на Java, чтобы задействовать такие мощные механизмы. Но я буду расти в эту сторону, спасибо большое, Элли, за такой интересный урок.
6. Задачи
| Задачи |
|---|
| 1. Слабые ссылки Разберитесь в примере. Внутри метода main в нужном месте создайте слабую ссылку reference на объект monkey. Должны быть только используемые импорты. |
7. phanotom Reference
- Привет, Амиго!
- Привет, Риша!
- Ну, как день прошел?
- Отлично! Мне сегодня Билаабо рассказал про рекурсию, а Элли про слабые и мягкие ссылки.
- А про призрачные ссылки рассказывала?
- Ты про PhantomReference? Упоминала, но не рассказывала подробно.
- Отлично, тогда надеюсь, ты не будешь против, если я заполню этот пробел.
- Конечно, я с удовольствием тебя послушаю, Риша!
- Отлично. Тогда я начну.
Призрачные(Phantom) ссылки – это самые слабые ссылки из всех. Только если на объект не остаётся никаких ссылок вообще, кроме призрачных, их механизм вступает в действие.

PhantomReference используется для сложной процедуры удаления объекта. Это может быть необходимо, когда объект что-то делает за границами Java-машины, например вызывает низкоуровневые функции ОС или пишет свое состояние в файл или еще что-нибудь очень важное.
Пример использования:
| Пример создания призрачных ссылок |
|---|
| //специальная очередь для призрачных объектов ReferenceQueue<Integer> queue = new ReferenceQueue<Integer>(); //список призрачных ссылок ArrayList<PhantomReference<Integer>> list = new ArrayList<PhantomReference<Integer>>(); //создаем 10 объектов и добавляем их в список через призрачные ссылки for ( int i = 0; i < 10; i++) { Integer x = new Integer(i); list.add(new PhantomReference<Integer>(x, queue)); } |
Еще раз обращаю внимание на последнюю строчку. В PhantomReference передается не только объект x, но и специальная очередь призрачных ссылок.
- А зачем нужна эта очередь?
- Вот сейчас и расскажу.
При уничтожении объекта, удерживаемого призрачной ссылкой, он уничтожается, но не удаляется из памяти! Вот такая вот загогулина, понимаешь.
- А это как?
- Тут довольно много нюансов, так что начну с самого простого.
Если на объект остаются только призрачные ссылки, то вот что его ждет:
Шаг 1. Во время ближайшей сборки мусора у объекта будет вызван метод finalize(). Но, если метод finalize() не был переопределен, этот шаг пропускается, а выполнится сразу шаг 2.
Шаг 2. Во время следующей сборки мусора, объект будет помещен в специальную очередь призрачных объектов, из которой будет удален, когда у PhantomReference вызовут метод clear().
- А кто его вызовет? Ведь объект-то как бы удален, разве нет?
- Тут дело в том, что фактически объект умер в нашем (Java) мире, но не исчез, а остался в нем призраком – на него хранится ссылка в очереди призрачных объектов. Та самая ReferenceQueue, ссылку на которую мы так заботливо передаем в конструктор PhantomReference.
- Т.е. эта ReferenceQueue - это как бы потусторонний мир?
- Скорее, как мир призраков.
И чтобы удалить объект-призрак, надо вызвать clear() у его призрачной ссылки.
Вот как можно продолжить предыдущий пример:
| Пример создания призрачных ссылок |
|---|
| //специальная очередь для призрачных объектов ReferenceQueue<Integer> queue = new ReferenceQueue<Integer>(); //список призрачных ссылок ArrayList<PhantomReference<Integer>> list = new ArrayList<PhantomReference<Integer>>(); //создаем 10 объектов и добавляем их в список через призрачные ссылки for ( int i = 0; i < 10; i++) { Integer x = new Integer(i); list.add(new PhantomReference<Integer>(x, queue)); } //взываем сборщик мусора, надеемся, что он нас послушается :) //он должен убить все «призрачно достижимые» объекты и поместить их в очередь //призраков System.gc(); //достаем из очереди все объекты Reference<? extends Integer>referenceFromQueue; while ((referenceFromQueue = queue.poll()) != null) { //выводим объект на экран System.out.println(referenceFromQueue.get()); //очищаем ссылку referenceFromQueue.clear(); } |
- Что что-то тут происходит – это понятно. Даже почти понятно, что именно происходит.
Но как это использовать на практике?
- Вот тебе более адекватный пример:
| Пример создания призрачных ссылок |
|---|
| //специальная очередь для призрачных объектов ReferenceQueue<Integer> queue = new ReferenceQueue<Integer>(); //список призрачных ссылок ArrayList<PhantomInteger> list = new ArrayList<PhantomInteger>(); //создаем 10 объектов и добавляем их в список через призрачные ссылки for ( int i = 0; i < 10; i++) { Integer x = new Integer(i); list.add(new PhantomInteger (x, queue)); } |
| Эта нить будет следить за призрачной очередью и удалять оттуда объекты |
| Thread referenceThread = new Thread() { public void run() { while (true) { try { //получаем новый объект из очереди, если объекта нет - ждем! PhantomInteger ref = (PhantomInteger)queue.remove(); //вызвваем у него метод close ref.close(); ref.clear(); } catch (Exception ex) { // пишем в лог ошибки } } } }; //запускаем поток в служебном режиме. referenceThread.setDaemon(true); referenceThread.start(); |
| Это класс, унаследованный от PhantomReference, у него есть метод close() |
| static class PhantomInteger extends PhantomReference<Integer> { PhantomInteger(Integer referent, ReferenceQueue<? super Integer> queue) { super(referent, queue); } private void close() { System.out.println("Bad Integer totally destroyed!"); } } |
Мы тут сделали три вещи.
Во-первых, мы создали класс PhantomInteger, который унаследовали от PhantomReference<Integer>.
Во-вторых, у этого класса есть специальный метод – close(), ради вызова которого как бы все это и затевается.
В третьих, мы объявили специальную нить - referenceThread. Она в цикле ждет, пока в очереди призраков не появится еще один объект. Как только он появляется, она удаляет его из очереди призраков, а затем вызывает у него метод close(). А затем метод clear(). И все – призрак может переходить в следующий лучший мир. В нашем он нас больше не побеспокоит.
- Как интересно, однако все вышло.
- Мы фактически отслеживаем очередь умирающих объектов, и потом для каждого можем вызвать специальный метод.
Но, учти, ты не можешь вызвать метод самого объекта. Ссылку на него получить нельзя! Метод get() у PhantomReference всегда возвращает null.
- Но ведь мы же наследуемся от PhantomReference!
- Даже внутри наследника PhantomReference, метод get() возвращает null.
- Тогда я просто сохраню ссылку на объект в конструкторе :)
- Ага. Но тогда эта ссылка будет StrongReference, и PhantomReference не вызовется никогда!
- Блин. Ладно, сдаюсь. Нельзя так нельзя.
- Вот и отлично. Надеюсь, ты вынесешь для себя что-то ценное из сегодняшнего урока.
- Да тут столько нового материала. А я думал, что уже все знаю. Спасибо тебе за урок, Риша.
- Пожалуйста. Все, иди отдыхай. Но не забудь, у нас вечером еще урок.
8. Задачи
| Задачи |
|---|
| 1. Призрачные ссылки Разберитесь в примере. Реализуйте логику метода getFilledList класса Helper: 1) создайте список, который сможет хранить призрачные ссылки на объекты Monkey 2) добавьте в список 200 ссылок, используйте очередь helper.getQueue() 3) верните заполненный список |
| 2. Кэширование Класс Cache - универсальный параметризированный класс для кеширования объектов. Он работает с классами(дженерик тип Т), у которых обязан быть: а) публичный конструктор с одним параметром типа K б) метод K getKey() с любым модификатором доступа Задание: 1. Выберите правильный тип для поля cache. Map<K, V> cache должен хранить ключи, на которые есть активные ссылки. Если нет активных ссылок на ключи, то они вместе со значениями должны автоматически удаляться из cache. 2. Реализуйте логику метода getByKey: 2.1. Верните объект из cache для ключа key 2.2. Если объекта не существует в кэше, то добавьте в кэш новый экземпляр используя рефлекшн, см. п.а) 3. Реализуйте логику метода put: 3.1. Используя рефлекшн получите ссылку на метод, описанный в п.б) 3.2. Используя рефлекшн разрешите к нему доступ 3.3. Используя рефлекшн вызовите метод getKey у объекта obj, таким образом Вы получите ключ key 3.4. Добавьте в кэш пару <key, obj> 3.5. Верните true, если метод отработал корректно, false в противном случае. Исключения игнорируйте. |
9. Logger
- А, вот ты где! Ты не забыл, что у нас сегодня еще одна лекция?
- Нет, я как раз тебя искал. Почти…
- Отлично, тогда начнем. Сегодня я хочу рассказать тебе про логирование.
Лог – это список произошедших событий. Почти как «морской журнал» или «дневник». Ну, или Твиттер – кому что ближе. А, соответственно, логгер это объект, с помощью которого можно вести логирование.
В программировании принято логировать практически все. А в Java – так вообще все и даже немного больше.
Дело в том, что Java-программы – это очень часто большие серверные приложения без UI, консоли и т.д. Они обрабатывают одновременно запросы тысяч пользователей, и нередко при этом возникают различные ошибки. Особенно, когда разные нити начинают друг другу мешать.
И, фактически, единственным способом поиска редко воспроизводимых ошибок и сбоев в такой ситуации есть запись в лог/файл всего, что происходит в каждой нити.
Чаще всего в лог пишется информация о параметрах метода, с которыми он был вызван, все перехваченные ошибки, и еще много промежуточной информации.
Чем полнее лог, тем легче восстановить последовательность событий и отследить причины возникновения сбоя или ошибки.
Иногда логи достигают нескольких гигабайт в сутки. Это нормально.
- Нескольких гигабайт? О_о
- Ага. Чаще всего при этом, лог-файлы автоматически архивируются, с указанием дня – за какой день это архив с логом.
- Ничего себе.
- Ага. Изначально в Java не было своего логгера, что привело к написанию нескольких независимых логгеров. Самым распространенным из них стал log4j.
Спустя несколько лет, в Java все же был добавлен свой логгер, но его функциональность была гораздо беднее и большого распространения он не получил.
Факт, как говорится, на лицо – в Java есть официальный логгер, но все сообщество Java-программистов предпочитает пользоваться другим.

На основе log4j потом было написано еще несколько логгеров.
А затем для них всех был написан специальный универсальный логгер slf4j, который сейчас повсеместно используют. Он очень похож на log4j, поэтому я расскажу тебе логирование на его примере.
Весь процесс логирования состоит из трех частей.
Первая часть – это сбор информации.
Вторая часть – это фильтрование собранной информации.
Третья часть – это запись отобранной информации.
Начнем со сбора. Вот типичный пример класса, который ведет лог:
| Класс с логированием | |
|---|---|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
class Manager { private static final Logger logger = LoggerFactory.getLogger(Manager.class); public boolean processTask(Task task) { logger.debug("processTask id="+task.getId()); try { task.start(); task.progress(); task.compleate(); return true; } catch(Exception e) { logger.error("Unknown error", e); return false; } } } |
Обрати внимание на слова, выделенные красным.
Строка 3 – создание объекта logger. Такой статический объект создают практически в каждом классе! Ну, разве что кроме классов, которые ничего не делают, а только хранят данные.
LoggerFactory – это специальный класс для создания логгеров, а getLogger – это его статический метод. В него обычно передают текущий класс, хотя возможны различные варианты.
Строка 7 – в логгер пишется информация о вызове метода. Обрати внимание – это первая строчка метода. Только метод вызвался – сразу пишем информацию в лог.
Мы вызываем метод debug, это значит, что важность информации «уровня DEBUG». Этот факт используется на уровне фильтрации. Об этом я расскажу через пару минут.
Строка 17 – мы перехватили исключение и… сразу же записали его в лог! Именно так и нужно делать.
На этот раз мы вызываем метод error, что сразу придает информации статус «ERROR»

- Пока вроде все ясно. Ну, насколько это может быть ясно в середине разговора.
- Отлично, тогда перейдем к записи фильтрации.
Обычно, у каждого лог-сообщения есть своя степень важности, и, используя ее можно часть этих сообщений отбрасывать. Вот эти степени важности:
| Степень важности | Описание |
|---|---|
| ALL | Все сообщения |
| TRACE | Мелкое сообщение при отладке |
| DEBUG | Сообщения важные при отладке |
| INFO | Просто сообщение |
| WARN | Предупреждение |
| ERROR | Ошибка |
| FATAL | Фатальная ошибка |
| OFF | Нет сообщения |
Эти уровни используются еще и при отсеве сообщений.
Скажем, если выставить уровень логирования в WARN, то все сообщения, менее важные, чем WARN будут отброшены: TRACE, DEBUG, INFO.
Если выставить уровень фильтрации в FATAL, то будут отброшены даже ERROR'ы.
Есть еще два уровня важности, которые используются при фильтрации – это OFF – отбросить все сообщения и ALL – показать все сообщения (не отбрасывать ничего).
- А как настраивать фильтрацию и где?
- Сейчас расскажу.
Обычно настройки логгера log4j задаются в файле log4j.properties.
В этом файле можно задать несколько appender’ов – объектов, в которые будут писаться данные. Есть источники данных, а есть – аппендеры – противоположные по смыслу объекты. Объекты, куда как бы «стекают» данные, если их можно представить в виде воды.
Вот тебе несколько примеров:
| Запись лога в консоль | |
|---|---|
| 1 2 3 4 5 6 7 8 9 10 |
# Root logger option log4j.rootLogger=INFO, stdout # Direct log messages to stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target=System.out log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} |
Строки 2 и 5 – это комментарии
Строка 3 – мы указываем уровень сообщений, которые оставляем. Все менее важные уровни будут отброшены (DEBUG,TRACE)
Там же, через запятую, мы указываем имя объекта (сами придумываем), куда будет писаться лог. В строках 6-9 идут его настройки.
Строка 6 – указываем тип апендера – консоль (ConsoleAppender).
Строка 7 – указываем, куда именно будем писать - System.out.
Строка 8 – задаем класс, который будет управлять шаблонами записей – PetternLayout.
Строка 9 – задаем шаблон для записи, который будет использоваться. В примере выше это дата и время.
А вот как выгладит запись в файл:
| Запись лога в файл | |
|---|---|
| 1 2 3 4 5 6 7 8 9 10 11 |
# Root logger option log4j.rootLogger=INFO, file # Direct log messages to a log file log4j.appender.file=org.apache.log4j.RollingFileAppender log4j.appender.file.File=C:\\loging.log log4j.appender.file.MaxFileSize=1MB log4j.appender.file.MaxBackupIndex=1 log4j.appender.file.layout=org.apache.log4j.PatternLayout log4j.appender.file.layout.ConversionPattern= %-5p %c{1}:%L - %m%n |
Строка 3 задает уровень фильтрации сообщений и имя объекта-апендера (стока).
Строка 6 - указываем тип апендера – файл (RollingFileAppender).
Строка 7 – указываем имя файла – куда писать лог.
Строка 8 – указываем максимальный размер лога. При превышении размера, начнет писаться новый файл.
Строка 9 – указываем количество старых файлов логов, которые надо хранить.
Строки 10-11 – задание шаблона сообщений.
- Я не знаю, что тут происходит, но догадываюсь. Что не может не радовать.
- Это отлично. Тогда вот тебе пример, как писать лог в файл и на консоль:
| Запись лога на консоль и в файл | |
|---|---|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# Root logger option log4j.rootLogger=INFO, file, stdout # Direct log messages to a log file log4j.appender.file=org.apache.log4j.RollingFileAppender log4j.appender.file.File=C:\\loging.log log4j.appender.file.MaxFileSize=1MB log4j.appender.file.MaxBackupIndex=1 log4j.appender.file.layout=org.apache.log4j.PatternLayout log4j.appender.file.layout.ConversionPattern= %-5p %c{1}:%L - %m%n # Direct log messages to stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target=System.out log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} |
- Ага, оказывается и так можно? Это же отлично!
- Ага. Ты можешь объявить сколько угодно апендеров и настроить каждый из них по-своему.
Более того, каждому апендеру можно очень гибко настроить фильтр его сообщений. Мы можем не только задать каждому апендеру свой уровень фильтрации сообщений, но и отфильтровать их по пакетам! Вот для чего надо указывать класс при создании логгера (я про LoggerFactory.getLogger).
Пример:
| Запись лога на консоль и в файл | |
|---|---|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# Root logger option log4j.rootLogger=INFO, file, stdout # Direct log messages to a log file log4j.appender.file=org.apache.log4j.RollingFileAppender log4j.appender.file.threshold=DEBUG log4j.appender.file.File=C:\\loging.log log4j.appender.file.MaxFileSize=1MB log4j.appender.file.MaxBackupIndex=1 log4j.appender.file.layout=org.apache.log4j.PatternLayout log4j.appender.file.layout.ConversionPattern= %-5p %c{1}:%L - %m%n # Direct log messages to stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.threshold=ERROR log4j.appender.stdout.Target=System.out log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} log4j.logger.org.springframework=ERROR log4j.logger.org.hibernate=ERROR log4j.logger.com.javarush=DEBUG log4j.logger.org.apache.cxf=ERROR |
Строки 6 и 15 – мы задаем свой уровень фильтрации для каждого апендера.
Строки 20-23 мы указываем имя пакета и тип фильтрации его сообщений. «log4j.logger» - это префикс, имя пакета выделено оранжевым.
- Ничего себе? Даже так можно. Ну, круто!
- Кстати, ни log4j, ни slf4j не входят в JDK, скачивать их надо отдельно. Это можно сделать вот тут. Но есть и второй способ:
Шаг 1. Добавляешь в класс импорты:
| import org.slf4j.Logger; import org.slf4j.LoggerFactory; |
Шаг 2. Становишься курсором на эти строчки и нажимаешь Alt+Enter в Intellij IDEA
Шаг 3. Выбираешь пункт Fine jar on web.
Шаг 4. Выбираешь – slf4j-log4j13.jar
Шаг 5. Указываешь, куда скачать библиотеку (jar)
Шаг 6. Пользуешься нужными тебе классами.
- Ничего себе! Да что же сегодня за день-то такой. Столько нового и столько классного!
- Вот тебе еще хорошая статья по логингу: http://habrahabr.ru/post/113145/
Ладно, все. Иди отдыхай, программист.
10. Задачи
| Задачи |
|---|
| 1. Настраиваем логгер Дан файл log4j.properties, который содержит настройки для логгера для разработчиков. Изменились требования к логированию для продакшена. Список изменений, которые нужно сделать: 1) Размер файла для логирования не должен превышать 5 мегабайт 2) Файлы лога должны храниться на диске D в директории log, называться должны runApp.log 3) Файлы лога должны содержать 6 последних файлов. Если шестой файл уже заполнен(имеет размер 5Мб), то нужно удалить самый первый и создать новый. 4) Уровень вывода сообщений в консоль нужно установить на уровне ERROR 5) Минимальный уровень логирования выставить в WARN |
11. Учимся гуглить
- Привет, Амиго!
Продолжаем наши уроки – учимся гуглить.
Вот тебе несколько заданий:
| Что надо найти в Google | |
|---|---|
| 1 | Как работает сборщик мусора в Java |
| 2 | Какие бывают виды сборщиков мусора |
| 3 | Что такое «поколения» объектов |
| 4 | Для чего используется SoftReference |
| 5 | Пример использования SoftReference |
| 6 | Пример использования WeakReference |
| 7 | Зачем нужен WeakHashMap |
| 8 | Что такое логгер |
| 9 | Как настроить логгер |
| 10 | Настройки логгера |
12. Профессор дает доп. материал
- Привет, Амиго!
Вот тебе дополнительный материал по теме.
13. Хулио
- Привет, Амиго!
- Привет, Хулио. Чем занимаешься?
- Да вот, решил заказать пиццу, и посмотреть хорошее видео.
- Отличная идея, а что будем смотреть?
- Как что? Конечно, новый блокбастер, называется "Пингвины атакуют".
- Что-то новенькое, ну давай посмотрим.
14. Вопросы к собеседованию по этой теме
- Привет, Амиго!
| Вопросы к собеседованиям | |
|---|---|
| 1 | Что такое сборка мусора? |
| 2 | Когда вызывается метод finalize? |
| 3 | Что произойдет, если в методе finalize возникнет исключение? |
| 4 | Что такое SoftReference? |
| 5 | Что такое WeakReference? |
| 6 | Что такое PhantomReference? |
| 7 | Как работает WeakHashMap? Где он используется? |
| 8 | Зачем нужно передавать очередь в конструктор PhantomReference? |
| 9 | Зачем нужен логгер? |
| 10 | Какие настройки логгера вы знаете? |
15. Большая задача
- Привет, боец!
- Поздравляю тебя с повышением уровня квалификации. Нам нужны отчаянные парни.
- Уверен, у тебя есть еще много нерешенных задач. Самое время решить парочку из них!